
数据结构是一种收集和组织数据的方式,以便我们可以有效地对这些数据执行操作。数据结构是关于根据某种关系呈现数据元素,以便更好地组织和存储。例如,我们有一些数据,玩家的名字“Virat”和年龄26。这里“Virat”是字符串数据类型,26 是整数数据类型。
数据结构的基本类型
正如我们上面所讨论的,任何可以存储数据的东西都可以称为数据结构,因此 Integer、Float、Boolean、Char 等都是数据结构。它们被称为原始数据结构。
数据结构也可以根据以下特征进行分类:
| 特色 | 描述 |
| 线性 | 在线性数据结构中,数据项以线性顺序排列。示例:数组 |
| 非线性 | 在非线性数据结构中,数据项不是按顺序排列的。示例:树、图 |
| 同质 | 在同构数据结构中,所有元素都属于同一类型。示例:数组 |
| 非均质 | 在非同构数据结构中,元素可能属于也可能不属于同一类型。示例:结构 |
| 静止的 | 静态数据结构是那些其大小和结构相关的内存位置在编译时是固定的。示例:数组 |
| 动态的 | 动态结构是根据程序需要及其执行而扩展或收缩的结构。此外,它们相关的内存位置也会发生变化。示例:使用指针创建的链表 |
关于Algorithm算法
算法是一组有限的指令或逻辑,按顺序编写,以完成某个预定义的任务。算法不是完整的代码或程序,它只是问题的核心逻辑(解决方案),可以用伪代码的非正式高级描述或流程图来表示。
每个算法必须满足以下属性:
- 输入- 应该有 0 个或多个从外部提供给算法的输入。
- 输出- 应该至少获得 1 个输出。
- 确定性——算法的每一步都应该清晰明确。
- 有限性——算法应该有有限的步数。
- 正确性——算法的每一步都必须生成正确的输出。
如果算法执行时间更短且占用的内存空间更少,则称该算法高效且快速。算法的性能是根据以下属性来衡量的:
- 时间复杂度
- 空间复杂度
数据结构和算法结合在一起,允许程序员构建他们想要的任何计算机程序。对数据结构和算法的深入研究确保了良好优化和高效的代码。
数据结构和算法如何协同工作?
有许多用于不同目的的算法。它们以相同的计算复杂度与不同的数据结构交互。将算法视为与静态数据结构交互的动态底层部分。
数据在代码中的表达方式是灵活的。一旦你了解了算法是如何构建的,你就可以在不同的编程语言中进行泛化。从某种意义上说,这有点像了解相关的语言家族在句法上的工作方式。一旦您了解了编程语言背后的基本规则及其组织原则,您就可以更轻松地在不同语言之间切换并更快地学习每种语言。
CS代考案例:COMPSCI 2201算法和数据结构,80+高分通过
Question 1:
- A hash function, h(x), hashes a name, x (the hash key), onto a hash value (the index into an array) as listed in the following table. The hash table has a length of 10 (indexed from 0 to 9). The keys are inserted into a hash table in the order listed in the following table.
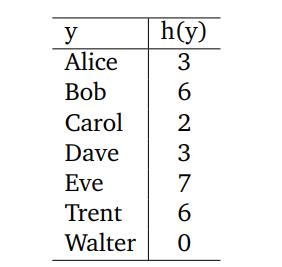
Show the table contents after insertion with:
i. chaining
ii. linear probing
iii. quadratic probing
(b) In lectures, on insertion into a skiplist we flipped a coin until a head occured to determine the height of an element. So for example, if we flipped two tails before a head then we would insert an element of height 3. In all the examples in lectures the probability of flipping a head was exactly 1/2.
Now assume that the coin is biased so the probability of flipping a head on a given throw is now 9/10. Derive an expression for the probability of producing an element of height h with this biased coin. Describe in broad terms the consequence of this bias in terms of the average cost of insertion into the skiplist.
Question 2
(a) What is the average cost of find on a binary search tree generated by the insertion of the elements:
10, 1, 6, 9, 7, 3, 2, 8, 4, 5
into an empty tree. Show your working. Note, you can give your answer as a fraction (no need to reduce it to decimal form).
- Prove by induction that a tree with n nodes has n-1 edges. (c) Draw a sequence of diagrams showing the insertion of the values:
[1,3,8,2,7,9,6,4,5] into an empty AVL tree, in the order shown above.
You must:
• Show the resulting tree immediately after each insertion step (that is before any balancing has taken place).
• Indicate the node(s) at which each rotation is performed.
• Where there is a double rotation, show the tree after each single rotation.
• Show the resulting tree after balancing operation(s).
Question 3:
(a) Write pseudo-code for an algorithm that performs breadth-first search of a directed graph: G = (V, E) and prints out all of the nodes visited.
- The following questions relate to traversals of directed graphs i. The graph-search algorithms shown in lectures always keep track of visited nodes because failing to do so can result in non-termination. Draw a graph that will lead to non-termination of Depth-FirstSearch if we fail to keep track of nodes already visited.
- ii. Under what conditions can the Single-Source-Shortest-Path problem be solved using Breadth-First-Search?
- (c) State the storage requirements of a graph with n nodes and m edges using: 1. an adjacency list, and 2. an adjacency matrix briefly justify each answer.






