大数据分析描述了在大量原始数据中发现趋势、模式和相关性以帮助做出基于数据的决策的过程。这些过程使用熟悉的统计分析技术(如聚类和回归),并在更新工具的帮助下将它们应用于更广泛的数据集。自 2000 年代初以来,大数据一直是一个流行词,当时软件和硬件功能使组织能够处理大量非结构化数据。从那时起,从亚马逊到智能手机的新技术为组织提供的大量数据做出了更大的贡献。随着数据的爆炸式增长,为存储和处理大数据而创建了 Hadoop、Spark 和 NoSQL 数据库等早期创新项目。随着数据工程师寻找方法来集成由传感器、网络、交易、智能设备、Web 使用等创建的大量复杂信息,该领域不断发展。即使是现在,大数据分析方法也正在与机器学习等新兴技术一起使用,以发现和扩展更复杂的洞察力。
Big Data Analytics的工作原理
大数据分析是指收集、处理、清理和分析大型数据集,以帮助组织操作其大数据。
1. 收集数据
每个组织的数据收集看起来都不同。借助当今的技术,组织可以从各种来源收集结构化和非结构化数据——从云存储到移动应用程序,再到店内物联网传感器等等。一些数据将存储在数据仓库中,商业智能工具和解决方案可以轻松访问它。对于仓库来说过于多样化或复杂的原始或非结构化数据可能会被分配元数据并存储在数据湖中。
2. 过程数据
收集和存储数据后,必须对其进行适当组织,以便在分析查询中获得准确的结果,尤其是在数据量大且非结构化时。可用数据呈指数级增长,使数据处理成为组织面临的挑战。一种处理选项是批处理,它随着时间的推移查看大型数据块。当收集和分析数据之间的周转时间较长时,批处理非常有用。流处理一次查看小批量数据,缩短收集和分析之间的延迟时间,从而更快地做出决策。流处理更复杂,而且通常更昂贵。
3. 清洁数据
大数据或小数据都需要清理以提高数据质量并获得更强的结果;所有数据的格式必须正确,任何重复或不相关的数据都必须消除或说明。肮脏的数据可能会掩盖和误导,从而产生有缺陷的见解。
4. 分析数据
将大数据变为可用状态需要时间。一旦准备就绪,高级分析流程可以将大数据转化为大洞察。其中一些大数据分析方法包括:
数据挖掘对大型数据集进行分类,通过识别异常和创建数据集群来识别模式和关系。
预测分析使用组织的历史数据来预测未来,识别即将到来的风险和机遇。
深度学习通过使用人工智能和机器学习对算法进行分层并在最复杂和抽象的数据中找到模式来模仿人类学习模式。
下面是一个Big Data Analytics的计算机作业代写高分案例:
Question 1. A bank is predicting the likelihood of default for each customer with an unbalanced data structure. The “No Default” cases occupy 80% of the data while the “Default” cases take up the remaining 20%. There are 1000 customers in the database. The confusion matrix for the model is:
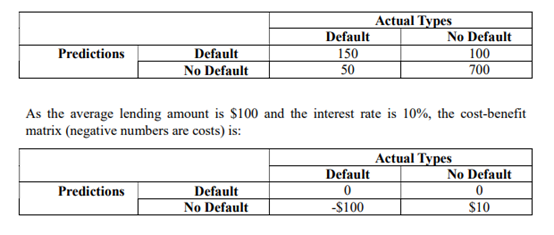
(a) Which group (“Default” or “No Default”) will you call positives?
(b) Calculate the followings:
(i) Plain accuracy
(ii) Error rate
(iii) True positive rate/ Sensitivity
(iv) False positive rate
(v) Specificity
(c) Calculate the overall expected value.
(d) Assume the same target percentage as in the first table. Write down the confusion
matrix for a random classifier.
(e) Calculate the overall expected value for the random classifier in (d).
Question 2. Two classifiers – A and B – are used to predict the probability of an increase in the Fed Funds rate. The predicted probabilities over the past 6 quarters are shown in the following table:

(a) Plot the ROC curves for the 2 classifiers and the random classifier. [Compute the TP and FP rates at the cutoff values: (0, 0.2, 0.4, 0.5, 0.6, 0.8, 1).]
(b) Comment on the 2 models. Which one is better?