哈希表基本上是一个数据结构,用来存储键值对。在C++中,哈希表使用哈希函数来计算数组中需要存储或搜索的值的索引。这个计算索引的过程被称为散列。哈希表中的值不是按照排序顺序存储的,在哈希表中存在巨大的碰撞机会,这通常是通过链式过程(创建一个具有所有值和与之相关的键的链表)解决的。
C++中的哈希表算法
下面给出了使用哈希函数在 C++ 中实现哈希表的分步过程:
- 将表大小初始化为某个整数值。
- 为键值对的声明创建哈希表结构 hashTableEntry。
- 创建 hashMapTable 的构造函数。
- 创建 hashFunction() 并找到哈希值,该哈希值将成为使用公式将实际数据存储在哈希表中的索引:
hash_value = hashFunction(key);
index = hash_value% (table_size)
- Insert()、searchKey() 和 Remove() 等函数分别用于键处元素的插入、键处的元素的搜索和键处的元素的移除。
- 调用析构函数销毁hashMapTable的所有对象。

哈希表如何在 C++ 中工作?
如上所述,哈希表存储指向实际数据/值的指针。它使用键来查找需要存储数据/值的索引。让我们借助下图来理解这一点:
| Key | Index (使用哈希函数) | Data |
| 12 | 12%10 = 2 | 23 |
| 10 | 10%10 = 0 | 34 |
| 6 | 6% 10 = 6 | 54 |
| 23 | 23 % 10 = 3 | 76 |
| 54 | 54 %10 = 4 | 75 |
| 82 | 81 %10 = 1 | 87 |
考虑哈希表大小为 10
哈希表中的元素位置将是:
0 1 2 3 4 5 6 7 8 9
| 34 | 87 | 23 | 76 | 75 | 54 |
下面是一个电影数据库的制作,使用C++编写一个程序通过哈希表存取来实现简单的数据搜索与查询。
Movie Data
When your program receives the movies command, it will be given a filename to read from. Each entry in
the file will look like:
Title
Year of Release
Runtime in Minutes
GenreCount GenreList
ActorCount ActorList
RoleCount RoleList
There will be no spaces in any of the data, for example instead of “John Wayne” we would have “John Wayne”. None of the fields will be blank, and GenreCount, ActorCount, RoleCount will all be ≥ 1. GenreList will have GenreCount entries, ActorList will have ActorCount entries, and RoleList will have RoleCount entries. Refer to the sample for more concrete examples. One strange thing about the data is that instead of the actors having names, they all have strings starting with “n” which we will refer to as “nconsts”. This is because there might be two actors with the same name, so we instead use a unique identifier. However, there is another command actors which also gives a filename. The structure of the actors file is much simpler with each line consisting of:
nconst ActorName
The third major operation is query. After the word query your program can expect input that looks like an entry from the movie file. However, it is also possible to have unknown values. If the title, runtime, or year are “?” it means that they are a wildcard and will match any movie. If the GenreCount, ActorCount or RoleCount are 0, it means they are a wildcard and will match any movie. When your program receives a query, it should search the hash table (more on that in a moment) and return all results that match. In order for two GenreLists, ActorLists, or RoleLists to match, they must have the same number of values, every value must match, and the values must be in the same order.
Choice of Hash Function and Table Implementation
The choice of the hash function is up to you. A good hash function should be fast, O(1) computation, and provide a random, uniform distribution of keys throughout the table. You may use one of the hash functions mentioned in lecture, one found on the internet, or one of your own devising. If you choose to download a hash function from the internet, you must provide the URL in your README and include the source code with your submission. If the downloaded file requires a copyright notice, you MUST include that notice. Be sure to observe any copyright restrictions on the use of the code. In your README file, describe your hash function and table implementation.
You may write as many classes as you feel are necessary, however you must have exactly one hash table and the representation must be a vector<pair<QUERY, list<MOVIE_DATA> > > where QUERY is your representation of a single query (may have wildcards), and MOVIE_DATA should be all the information about one movie. To handle collisions, use one of the open addressing methods described in lecture (linear probing, quadratic probing, or secondary hashing). Linear probing is the simplest of these three methods. Since you are not separate chaining, you might be confused about why the value has a list. Each entry in the hash table consists of a query, and a list of all movies that match that specific query. You should not add a movie’s data to a particular list in the hash table unless it matches the corresponding key (query). You will receive a significant penalty if you do not follow this structure.
You may not use std::hash, std::unordered map, std::unordered set, std::map or similar STL functions/containers.
Exception: You can use a map to store actor data, but not movie data. When implementing the hash table, set the initial size of the table. As you enter data in the table, calculate the occupancy ratio:
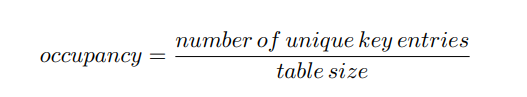
When the occupancy >than some fixed level, double the size of the table and rehash the data. Describe your re-sizing method in the hash table section of the README file.

Input/Output & Basic Functionality
The program should read a series of commands from std::cin (STDIN) and write responses to std::cout (STDOUT). Sample input and output files have been provided. You can redirect the input and output to your program using the instructions in the section Redirecting Input & Output found at http:
//www.cs.rpi.edu/academics/courses/spring22/csci1200/other_information.php
Your program should accept the following commands:
• movies filename – Read movie data from filename.
• actors filename – Read actor data from filename.
• table size N – this is an optional command. N is an integer. It is the initial hash table size. If it does not appear in the command file, the initial table size should be set to 100.
• occupancy f – this is an optional command. f is a float. When the occupancy goes above this level, the table should be resized. If it does not appear in the command file, the initial level should be set to 0.5.
• query query data – Search the movie data for any matches to query data.
• quit – Exit the program.